Advanced ID Resolution
Statsig warehouse native natively supports resolving multiple IDs to one identified user, allowing you to easily expose an experiment on one identifier and analyze data coming from one to many mapped identities associated with that experimental unit.
Common scenarios where this is used are:
- Exposing logged out users and analyzing logged-in metrics like revenue or a funnel going from logged-out marketing page landing -> to a logged-in subscription purchase
- Utilizing one:many relationships, e.g. a single user owns multiple accounts. ID resolution lets you aggregate metric from the user's mapped accounts
ID resolution is a common need in experimentation; generally the responsibility for this mapping is put onto data users or PMs running experiment analysis, which leads to inconsistent results and expensive query logic. Using Advanced ID Resolution streamlines the process, making it consistent and performant and allowing all users to point to trusted identity tables.
The Identity Challenge
A common problem in experimentation is trying to connect different user identifiers before or after some event boundary, most frequently signups.
In these scenarios, the experimenter will have a logged-out identifier (e.g. a cookie or a Statsig stableID) as well as - for those who do sign up - a userID generated after the user signs up. Because business metrics are generally calculated at the grain of userID, it's common to want to run an experiment where the unit of analysis is a logged out identifier, but the evaluation criteria for the experiment is a logged-in metric (e.g. purchase revenue, or estimated Lifetime Value).
Many platforms handle this in an ad-hoc way, which requires the user to do pre-processing to join and deduplicate exposures, or tagging userID metrics with an associated logged-out identifier. This is tractable, but leads to you having to manage and debug fairly complex queries resolving identifiers across timestamps and joining mapping tables to your source-of-truth fact tables..
Statsig Warehouse Native offers an automatic, no-code solution for connecting identifiers across this boundary in a centralized and reproducible way.
Mapping Modes
When using Advanced ID resolution, you can choose between modes:
- Strict 1:1 mapping enforces that identities have a singular mapping. If you have a mapping between two IDs that are always 1:1, this mode enforces that the mapping is singular and warns you if there's data where that's to the case. Users with a single identity can use downstream metrics from the secondary identity, and multi-mapped users are considered corrupted and discarded from the analysis
- First-touch mapping is for cases where units might have multiple mappings, in either direction. For example, a single user may have multiple "profiles", or someone may have logged into the same account from several devices or web sessions. In this case, units will use the experiment group of their first exposure for analysis, and aggregate metrics from all of their associated secondary IDs.
| Strict 1:1 Mapping | First Touch Mapping |
|---|---|
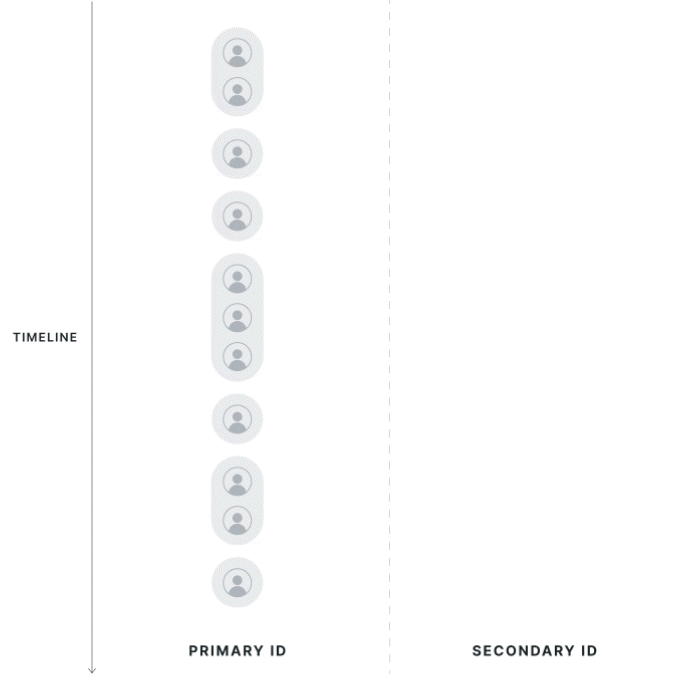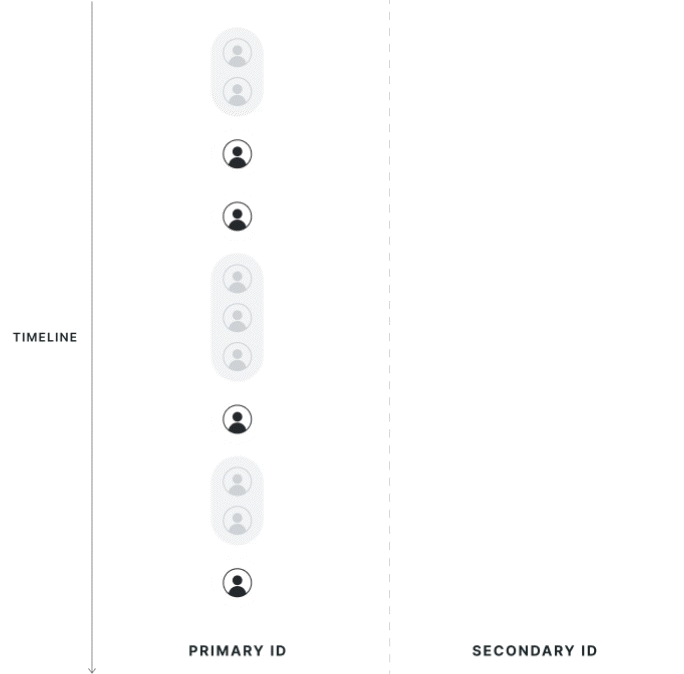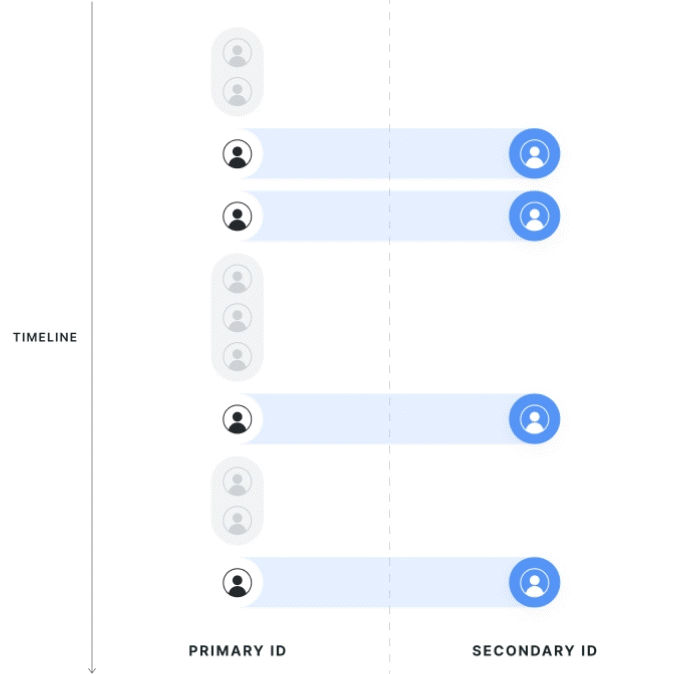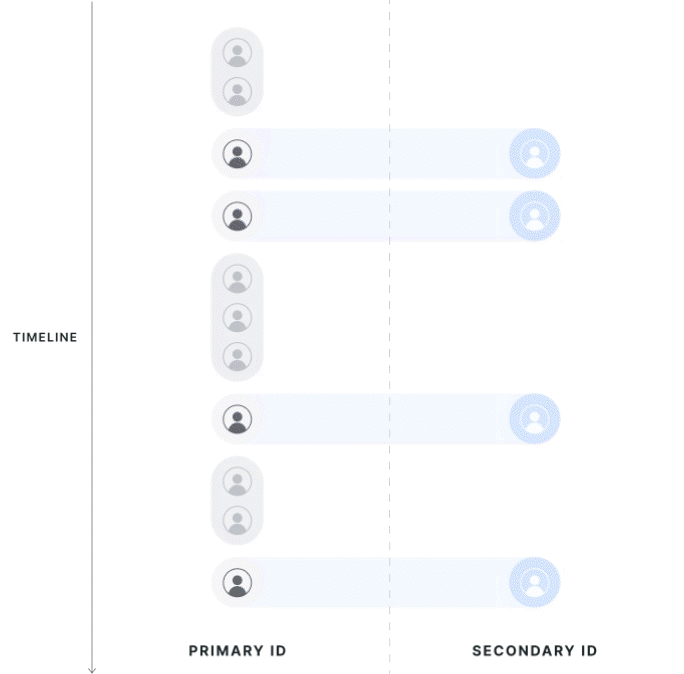 | 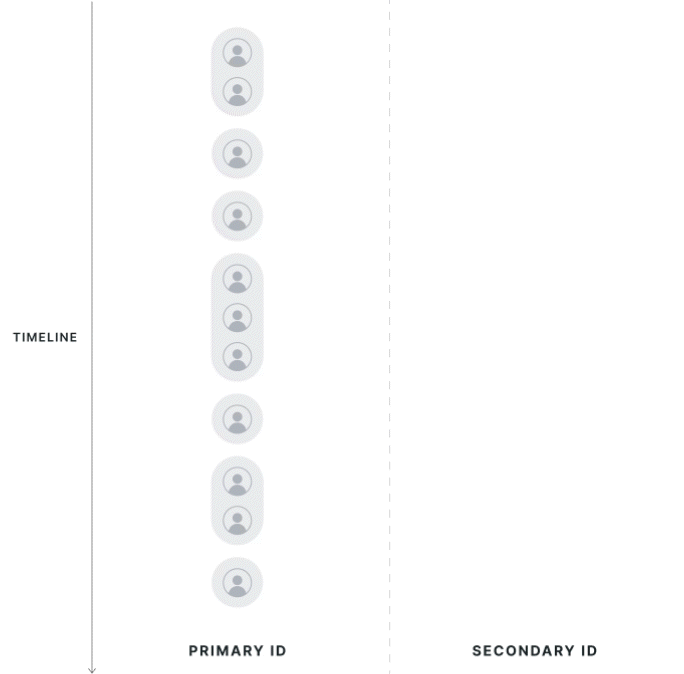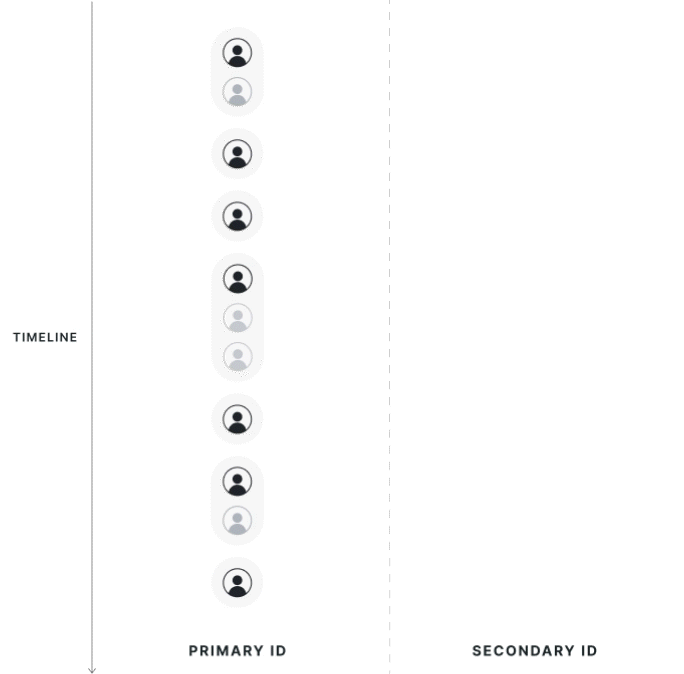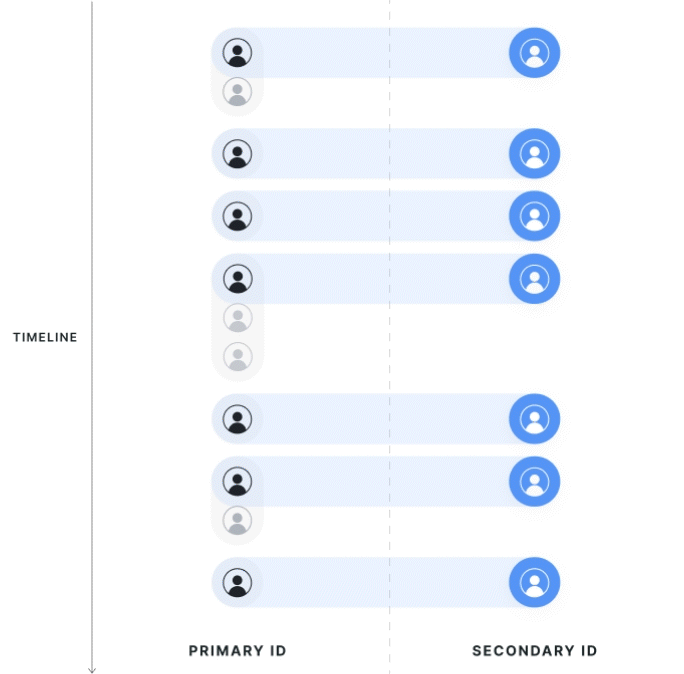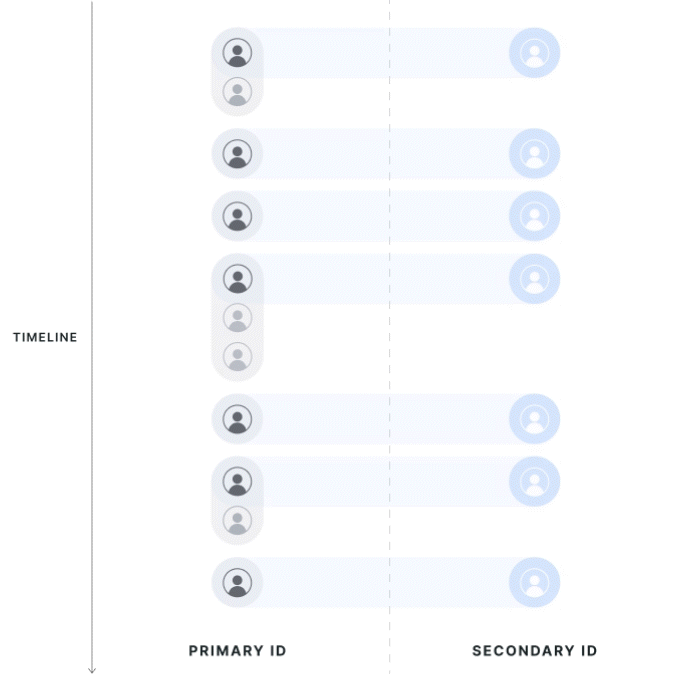 |
Strict 1:1 Mapping
All potential mappings between identifiers within the experiment date range, on the exposed population, are collected. If the primary ID has multiple secondary IDs, or vice versa, it is considered polluted and dropped from the analysis.
First Touch Mapping
The direction of first-touch mapping will be based on the experiment; all secondary IDs resolve to 1 primary ID, and a single primary ID can have multiple mapped secondary IDs. If your aim is to only have one secondary ID, you can manage that logic inside the entity property source today, but feel free to reach out to support if there's specific logic you would like to request.
Data is attributed to the group of the first associated primary ID seen in the exposure. If a secondary ID has multiple associated primary IDs, the group of the first primary ID will be used. Note that this means users that cross groups are not discarded from analysis but instead are assigned based on the the first experience they had.
Primary ID records that are associated with another Primary ID, but are not the first observed records, are dropped from the analysis. If a user is exposed twice on different primary IDs that resolve to the same secondary IDs, only the primary ID metrics from the first-exposed user will be kept in the analysis.
Last Touch Mapping (beta)
Same as first touch but data is attributed to the most recent primary ID.
Note on ID stitching
Multiple secondary IDs attached to one primary ID still count as "one" experimental primary ID; the metric values will be merged across records from the different secondary IDs - e.g. added in a sum metric or counted in a count metric.
We are interested in supporting more complex 1-to-many relationships of identities and are eager to partner with customers to develop these capabilities if a more advanced use-case is required.
How it Works
Setting up identity resolution in Statsig is very simple. You can either log or join data to provide both IDs on your assignment source, or provide one ID in the assignment source along with a mapping table between the IDs in the form of an Entity Property Source.
Using Property Source
To use Identity Resolution across experiments in your project, you will need a lookup table that has both the ID you are exposing on and the selected targeted ID. This table can be configured by setting up an Entity Property Source with both IDs present.
Once that's done, you can simply select this source when configuring your secondary ID type, and Statsig handles the join for you.
If you want to use a Statsig SDK to populate this table, you can log an event (like a "Signup" event that has both the logged-out identifier and the user ID on the same event. Events sent via the Statsig SDK are written into your warehouse - and you can configure an Identity Resolution source on top of that using something like this -
Using Assignment Source
When creating an assignment source, provide a column for both ID types. It is assumed that your 'Primary ID' will be non-null for exposure records. Your secondary ID can be null. If your secondary ID is sparse (some records are null, and some are not due to logging), Statsig will back-attribute any identified secondary ID to other records from the same Primary ID.
When you create an analysis-only experiment or power analysis with this ID type, you can optionally select a Secondary ID. If you do so, you can now use metrics from either ID type in your analysis. For E2E experiments that use the Statsig SDK, this is configurable on the experiment setup page, under Advanced settings.
Behind the scenes:
- For metric sources with the primary ID, metrics will be joined to exposures based on that primary ID
- For metric sources with only the secondary ID, metric will be joined to exposures based on that Secondary ID
- If using strict mode, users with a duplicate mapping are dropped from analysis. Using first-touch, units use their first exposure record, and merge data from all mapped secondary IDs.
This works natively across Metric Sources, so you can easily set up funnel or ratio metrics across the two ID types.
Analysis is done using the primary ID - this process associates metric values that are on an associated secondary ID.
Mapping Changes
If a change is made to the entity property source or assignment source's definition or underlying data, that will be reflected on the next reload. This is why a full reload is required, since otherwise historical changes to the mapping can lead to inconsistent data on incremental reloads or explore queries.
Best Practices
We strongly recommend using an Entity Property Source to provide a cleaned unit mapping from your warehouse. However, you can also provide mappings on your exposure source by logging multiple identifiers in the exposure data - Statsig will greedily use this to match across identifiers.
For both modes, an experiment can currently only have one mapped ID type - e.g. secondary_id->user_id, or secondary_id->account_id, but not both.
All modes will require a full reload, so that there's not data inconsistency due to historical mappings being changed or new mappings introduced.
The property source or assignment source used to provide mappings will be filtered to records within the experiment's date range. If a mapping is "evergreen", or not scoped to a specific time period, you can omit the timestamp on the entity property source.
Example of a supported schema
if your assignment source data contains:{stableID: 'unknown_123', exp_id: 'PDP Test', test_group: 'Control'}
and your metric sources contain data that represents a metric as:{userID: 'known_abc', event: 'page_load'}
Your Entity Source or Assignment source must contain the secondary identity (in this case, userID) that will enable Statsig to join your assignment data with your metric data:
{stableID: 'unknown_123', userID: 'known_abc', country: 'USA'}
Considerations
Deduplicating records can lead to biased results, so Statsig preforms two extra health checks on this kind of experiment.
- Statsig will check your deduplication rate and warn you if it is unusually high. It's expected that some secondary IDs will have multiple logged-out IDs due to users using different devices or clearing browser history
- Statsig will perform a chi-squared test evaluating if the deduplication rate is identical across arms of the experiment. In some cases, an experiment may cause more users to come back (for example an email resurrection campaign), in which case duplicates are expected to be more frequent in that arm and can be a positive outcome. In this case, you can perform first-touch attribution to maintain a common identifier